![[學AI] AI 為何讓職場更忙?從幻覺、落地摩擦到可控工作流](https://www.anguscheong.net/wp-content/uploads/2026/03/ai-mang-feng-mian-1080x675.jpeg)
by angus | 2026-03-03
很多職場人士都遇過這樣的場景。午飯後回到辦公室座位,公司電郵和內部通訊工具彈出幾條訊息:「客戶想要另一個方向」、「今晚八點前要出 revised deck」、「順便幫忙寫一封回覆,語氣要友善」。
此時,我們自然地打開 AI,輸入一句「幫我寫個 proposal」。畫面立刻出現一大段文字。看起來完整,有條理,還帶點顧問的味道。但手停在鍵盤上,心裡反而更慌。這段文字能直接交出去嗎?口吻像我們公司嗎?合規會不會出問題?數字靠不靠譜?最重要的是,這封信用公司名義發出去,最後負責的是誰?
於是,辦公室裡熟悉的循環又開始了。第一輪改到「差不多」,第二輪 AI 改得「走了樣」,第三輪同事說「不切實際」。最後主管走過來問:「重點是什麼?資料核對清楚沒有?」
這不是個別情況。最近 METR 做了一項研究。他們找來資深開源軟件開發者,用 2025 年的 AI 工具(比如 Cursor 加 Claude 3.5/3.7 Sonnet)完成真實開發任務,結果卻出人意料。平均花的時間多了 19%,但受試者開工前預期會快 24%,做完後還覺得自己快了 20%。該研究指出,這不代表 AI 讓所有人變慢,而是反映出現實中的問題。AI 輸出需要審核,人在壓力下容易過度依賴工具,資深人員也容易遇到效率提升越來越少的情況。
最讓人難受的不是「變慢」,而是「覺得變快了」。這種感覺就是所謂的「生產力幻覺」。
日常工作中的忙有兩種。一種是輸出忙(寫得多、改得多),另一種是責任忙(驗證、合規、負責)。AI 確實能減少輸出忙,但常常讓責任忙更嚴重。所以幻覺最容易出現在「可以生成,但難以驗證」。
以上情景的出現,背後其實有三件事正在同時發生,包括技術普及的速度跟不上實際應用,未來經濟潛在風險增加,以及我們的工作方式也在徹底改變。
能力像火箭,落地像蝸牛:AI 卡在三道牆
大家最近可能都有個疑問:既然 AI 已經厲害到可以自動寫APP、可以通過律師考試、可以自動生成電影級的影片,為什麼我們的 ERP 系統還是那麼難用?為什麼申請個流程還是要填表?
近日成為焦點的 Anthropic CEO Dario Amodei,曾用一個很有穿透力的框架解釋這種現象:我們正站在兩條曲線的撕裂點。
一條是能力曲線(Capability Curve)在上升,AI 能力像火箭升空,呈指數式增長;另一條是擴散曲線(Diffusion Curve)在慢行,技術真正落地到組織、流程與制度的速度,像蝸牛在爬。
想像一下,如果今天有人發明了「傳送門」,一站上去就能到達倫敦。理論上交通運輸業會被顛覆,但現實中,我們不可能明天就廢除機場和交通工具。政府要立法、城市要重新規劃、大眾要克服恐懼。傳送門再厲害,也頂不住「現實的審批流程」。
這就是我們現時的處境。AI 能力已經很強,但它撞上了現實世界的三道牆。
第一道牆是技術的最後一公里。AI 可以一秒寫出漂亮程式碼,但公司內部可能還是使用著二十年前的老系統。IP 設定錯誤、權限卡在人事部、資料庫命名混亂、接口沒有文檔……這些瑣碎細節,AI 不會自動替你走跨部門流程,最後仍要人一個一個去對接。
第二道牆是企業的慣性。新創公司可能五分鐘就部署好 AI,但大型機構要引入軟件工具,要過法務、過資安、算 ROI、開高層會議。AI 不能代簽、不能代責,會議也不會因為大語言模型更強而自動少一輪。官僚體制與技術革新的時差,很多時候就卡在這裡。
第三道牆是物理世界的束縛。就算 AI 一天能設計出抗癌藥,後面的動物實驗、人體臨床、監管審批仍要三到十年。生物反應的時間縮短不了,物理世界也不會像軟件一樣版本升級就加速。
所以,我們會覺得現實有些割裂。螢幕裡的 AI 像 2026 年的數碼天才,螢幕外的流程卻停在 2010 年。更諷刺的是,人類總以為自己在管理工具,直到某天發現真正管理我們的,是流程、權限與合規。
把 2028 當終點的壓力測試:AI 太成功會怎樣?
前面講完「慢」,要再講一段「快」。
今天我們覺得忙,很多時候來自制度還未吸收技術;一旦制度追上,忙的形態可能會變,甚至從忙轉向資源及工作的再分配。
近日,研究機構 Citrini Research 發布一份名為《The 2028 Global Intelligence Crisis》的報告,他們做了一個極端但很有啟發性的思想實驗。它用倒敘敘事把 2028 年當成終點,回推危機如何一路形成。核心問題是:假如 AI 太成功,產業結構會如何失衡?
報告提出了幾個關鍵的推演。
其一是「幽靈 GDP」(Ghost GDP)。它講的是 AI 把內容、程式碼、服務的產出拉到很高,宏觀數據很漂亮,但機器不會消費。這好比廚房出菜快如閃電,餐廳裡卻沒有客人吃。在這種有產出、無消費的情況下,經濟數據與普通人的體感就開始脫鉤。
其二是「摩擦歸零」(Friction Went to Zero)。它講的是未來 AI Agents(智能代理)幫人格價、訂機票、選保險。人會為品牌情感買單,而代理只看效率與數據。這樣,靠資訊不對稱與中介費生存的產業,可能被擠壓到利潤趨近於零。
其三是一條更嚴酷的價值鏈。白領被取代、消費萎縮、信貸收縮與連鎖反應,並假設 2028 年可能出現失業率超 10%、S&P 下跌近 40% 這一類的危機情景。這些數字當然是一種劇本式推演,重點不在它準不準,而在它逼我們看清現實,就是 AI 造成的衝擊,可能先落在白領,而不一定先落在藍領;加上政策與制度的滯後,會把這種衝擊放大。
這個報告出來之後,引發大量的討論,也帶來不少爭議,說它是一種敘事、製造恐慌。不過,有一點值得警惕的是,它提醒了我們,未來的競爭,不只在「誰做得更好」,還在「誰仍被需要」。很多人談 AI 只談模型有多強,卻避談價值鏈,像只看廚房火力有多猛,廚師的廚藝有多好,卻不看餐廳還有沒有客人。
AI四種用法四種代價:你是哪一派?
回到辦公室現場,其實我們已經分化出幾種很典型的 AI 使用流派。先把這些流派講清楚,後面再談怎樣把它們收束成一條可控的工作流。
第一,「傻瓜派」喜歡收集提示詞(Prompts)。其好處是新人上手快,交付風格一致;缺點是把模板當萬能鑰匙,遇到合規、政治敏感的灰度題,模板救不了判斷。比較穩的做法,是把模板當開場,中段補三樣東西:現狀、限制、驗收標準,讓 AI 有扶手可順著走。
第二,「救火派」講究速度,AI 出初稿就先頂上去。其好處是今晚要交貨,能救急就是好工具;缺點是永遠停留在「一鍵出結果」,後面用更多時間修改、補漏洞、向他人道歉。AI 像開得太大的水龍頭,火是熄了,辦公室也水浸了,最後大家忙著幫手拖地。更穩的做法,是救火可以,但每次用完補一點 QC,慢慢把救急變成常規。
第三,「兵器派」今天學這個工具,明天試那個模型。其好處是兵器庫夠嚇人,遇到突發事不容易卡死;缺點是先問用哪個工具,而不是先問要解決什麼問題。工具越多,流程越亂。比較務實的做法,是固定一套「釐清→拆解→規格→驗收」的流程,工具變成只是換個執行者。
第四,「快餐派」覺得 AI 寫得順眼就直接發出去。這樣做短時間內填飽肚子,感覺舒服。缺點是 AI 最危險的地方是既有內容,且看起來還像真的。一旦出錯,比如資料錯誤、承諾太多、語氣不對、違反規則,責任都由人來承擔。唯一能救這類做法的,就是一條鐵律:所有對外發出的內容,都必須有人檢查。
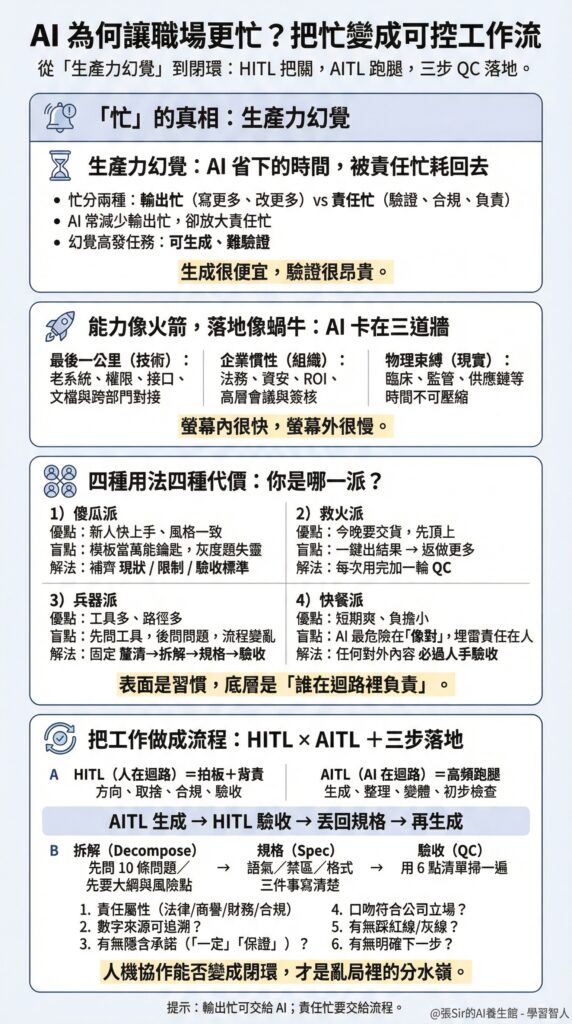
從以上的四個流派可以看出,表面上是不同的習慣,底層其實是「誰在迴路裡負責」:哪些步驟交給 AI 去完成,哪些步驟需要人把關。這就回到我一直以來提倡的兩個關鍵概念:HITL 與 AITL。
把工作做成產線:HITL 把關,AITL 跑腿
這場AI變革更像一次辦公室內部的工業革命。我們把原本依賴個人手藝、經驗、直覺的知識工作,拆成可標準化的生產線。哪一段生成、哪一段驗證、哪一段交付,邊界越清楚,修改就越少,責任也越可控。
HITL(Human-in-the-loop,人在迴路)是把關角色,像項目總監審核報告,審的不是格式細節,而是論點站不站得住腳、策略符不符合公司利益、有沒有踩合規紅線、有沒有把「可能」寫成「必然」。但方向與驗收由人拍板時,責任最後便落在真人身上,AI 則不會為人作賠償。
AITL(AI-in-the-loop,AI 在迴路)是跑腿角色。標準化、重複性高、耗時間的工作,例如整理會議記錄、做十個文案版本、找代碼錯誤、把散亂資訊變成清單等等,讓 AI 在迴路裡按指令縱橫就行。
因此,理想的工作流像一場接力賽。AI 生成與整理(AITL),人決策與驗收(HITL),再把規格與約束指令丟回 AI。很多人越用越忙,往往是因為把生成誤當完成,然後把最昂貴的責任成本留到最後一刻才補上去。
三步把 AI 關進流程:拆解、規格、QC 清單
不想被「生產力幻覺」困住,可以把工作變成三步。它看上去像增加流程,實際上是在降低重複修改的深淵,把耗時的責任提前處理掉。
首先是拆解(Decompose)。與其叫 AI「幫我寫個方案」,不如先叫它「幫我釐清下一步」。例如「先問我 10 條問題,了解目標和限制」、「幫我列出 5 個風險點」、「給出 3 個不同語氣的草稿選項」。把大任務拆碎,AI 就不容易亂填空,人也更早看見真正的風險。
其次是規格(Spec)。AI 不會讀心術,但它善於守規矩。我們可以把隨意寫成規格,例如語氣要專業但不油膩,少形容詞,多結論與依據;禁區要清楚,例如不要承諾業績、不要引用競品名字、不要寫超出授權的條款;格式也要定,例如先摘要,再列選項,最後給建議與下一步。規格越清楚,後面的 QC 成本就越低。
最後是驗收(QC)。把驗收變成標準動作,例如叫 AI「先出大綱再寫全文」、「標註所有你不確定的數據」、「列出這份方案可能的漏洞」。然後人用一個固定清單快速掃一遍:
這就是 HITL 的核心。我們不一定要親手寫每個字,但要負責判斷它值不值得發出去。
最後的勝負:閉環系統,而非爆款工具
我們正站在一個很奇妙的時間點。
一方面,Amodei 曾預測 AGI(通用人工智能)可能在 2026 或 2027 年出現,並警告這可能帶來就業大幅縮減、需要加速 AI 安全研究。這種預測充滿爭議,也不必當成時間表,這更像情景推演。然而,它也像警報器,提醒我們變化不一定會很慢。
另一方面,Citrini 用極端劇本提醒我們,當 AI 的能力開始侵蝕白領的價值鏈,衝擊可能先體現在消費與信貸,而不只是「多了幾個更好用的助手」。
對職場人士來說,焦慮很昂貴,因為它消耗判斷力。更化算的,是把注意力放回如何更好地落地,是否能回答:誰能把神級的能力嵌入平庸的現實?誰能打通老舊系統?誰能搞定跨部門流程?誰能把 AI 的產出變成安全、可交付、可追責的商業價值?
對企業來說,未來的競爭也不只在模型參數上,更在誰能把「交付成果」變成一門工程學:把任務拆解、把規格寫清、把驗收標準化。很多公司以為自己在買「降本增效」的工具,實際上買的是一面鏡子。它能照出自己流程有多亂、權責有多模糊、合規有多靠運氣。輸出的量雖然變便宜了,但付出去的成本反而變高了。如果沒看見這個現實,就很容易把忙碌當成努力,把善後當成敬業。
到最後,真正能站穩的團隊,靠的是一套閉環,而非某一個爆款工具。人類負責決策把關與驗收,AI 負責高效執行與整理,兩者來回迭代,讓效率、風險與責任都可控。閉環建立起來,我們才算駕馭這股力量,否則很容易被它的產出量淹沒。這也是我們團隊目前專注的方向,正在為自己的團隊及客戶企業搭建這樣的智能協作系統,讓技術真正落地,讓工作回歸價值、讓企業提升競爭力。
職場與企業不必糾結 AI 有多強,把它當作有潛力但不懂規矩的超級實習生便是。教流程、給標準、驗成果。人機協作能否變成閉環,才是亂局裡的分水嶺。
 建議下載收藏
建議下載收藏
參考資料:
Citrini Research. (2026). The 2028 global intelligence crisis [Report]. https://www.citriniresearch.com/p/2028gic
ForkLog. (2026). Anthropic CEO foresees imminent arrival of AGI and job reductions [News article]. https://forklog.com/en/anthropic-ceo-foresees-imminent-arrival-of-agi-and-job-reductions/
METR. (2025). Measuring the impact of early-2025 AI on experienced open-source developer productivity [Blog post]. https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/
YouTube. (2025). Dario Amodei: Anthropic CEO on Claude, AGI & the Future of AI & Humanity [Podcast]. https://youtu.be/ugvHCXCOmm4?si=qdtdV8yHDWkonudB
@張Sir的AI養生館 – 學習智人
![[學AI] AI 寫計劃書:速度很誘人,陷阱也很溫柔](https://www.anguscheong.net/wp-content/uploads/2026/02/XTfHUmF-dxoTklzHU4uAD_2752x1536_20260225_095659_raw-1080x675.jpg)
by angus | 2026-02-25
這兩天公司內部的節奏有點像坐過山車,昨晚才剛和同事A把那份「市場營銷報告」磨到深夜十一點,今早七點多,又和同事B在網絡會議室討論「投標計劃書」。
雖然面對的場景不同,使用的工具各異,但這兩份由 AI 協助產出的初稿,都散發著一種詭異的「共同氣味」——乍看之下,段落整齊、詞彙專業、厚度十足,像極了一份正經文件;但只要沉下心來細讀,就會發現它經不起推敲。沒有起承轉合的鋪陳,邏輯線若隱若現,更像是一本把各種材料強行拼貼起來的說明書。讀後,很難發自內心地感嘆一句:「原來公司的AI這麼厲害。」
看起來完成了,實際上只是把「文字」提交了
同事B的經歷特別典型:遇到不懂的操作先問技術同事C,再結合同事A手頭的資料,丟給 AI,轉眼間就能輸出一份 Word 文檔。這種效率確實驚人,也值得高興,因為它降低了技術門檻,讓很多原先需要長時間磨練的工作能更快上手。
但也正因為太快,很容易產生一種錯覺,以為自己已經把「計劃」做完了。其實,完成的只是文件的「外形」,而非方案的「骨架」。AI 能把版面填得很滿,但它無法替我們做商業判斷。我們的主張是否真的成立?假設的數據是否真實?流程在港澳的商業環境下能否落地?投入產出比是否合理?那些寫在紙上的承諾,我們是否承擔得起?
這些問題,必須由人緊緊握住方向盤來回答。
最大的坑:認知放棄,人逐漸退出迴路
以上的經驗,或許很多在職場的人士都遇到過。我最想提醒的是,一個聽起來有點學術,但發生在每個人身上的現象:「認知放棄」(Cognitive Surrender)。
簡單來說,一旦人類過度依賴 AI 的自動化流程,大腦就會本能地偷懶,不再深想、不再追問、不再審核,慢慢退化成一個只負責把稿子拼好、把格式調順的「排版工」。
說到這裡,必須再次引入一個我經常在文章中提及的核心概念:人在迴路(HITL, Human-in-the-loop)。用白話講就是——AI 可以跑流程,但每一個關鍵的十字路口,必須有人在場指揮;AI 可以寫代碼或文案,但最終的責任,必須有人來承擔。
因此,可怕的地方在於,這種「放棄」不是瞬間發生的,而是像溫水煮蛙一樣自然而然。第一次覺得「AI 寫得不錯」,第二次覺得「差不多可以了」,到了第三次,對那些明顯的邏輯漏洞也就「輕輕放過」。昨晚同事A那份報告就隱約有這種跡象。第一眼似模似樣,細看卻漏洞百出,這種東西如果直接發給客戶,撞板是遲早的事。效率看似上升了,但團隊的專業水平並沒有同步提高。
「寫得很詳細」不等於「做得到」
AI 有個特點,它特別擅長把內容寫得「很完整」,尤其在流程、步驟、職責分工、交付物這些環節,它能呈現出驚人的顆粒度。這也是同事B提到的感受:明明是不太懂的業務細節,AI 卻寫得頭頭是道。
這時候我們必須額外警惕。計劃書和投標文本一旦白紙黑字寫下「我們能做到」,在客戶看來這就是商業承諾,而不僅僅是一篇作文。AI 讓我們更容易寫出「像承諾」的漂亮句子,也更容易讓我們在沒想清楚之前就把承諾交進去。最終出事的時候,AI 可不會出席會議替我們解釋,更不會幫我們賠償。
如何善用 AI Agent 不會撞板?
為了把我在之前的文章中介紹過的一套AI與人類協作的邏輯具象化,我用AI畫了這樣一張簡潔的流程圖(見附圖):
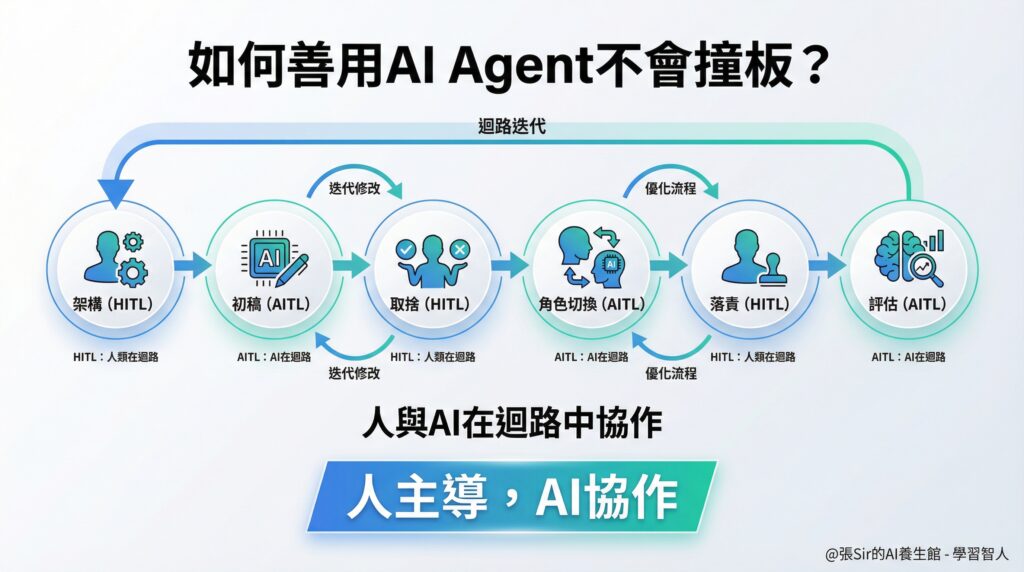
1. 架構(HITL):由人來定義目標與框架。
2. 供給(AITL):AI 負責快速生成素材與選項。
3. 取捨(HITL):人回來做判斷,篩選什麼可用,什麼是垃圾。
4. 角色切換(AITL):AI 根據反饋進行優化或模擬不同的視角,現在可以用多代理(multi-agents) 了。
5. 落責(HITL):人必須確認最終內容的可行性與責任歸屬。
6. 評估(AITL):AI 輔助進行最後的協作評價或合規檢查。
這張圖的核心在於節點間的切換和迴路迭代——人主導,AI 協作。
我自己剛開始寫一些內容時,也犯過沒有迴路的錯誤。覺得省時就一路用下去,結果在該嚴格的地方鬆懈了,在該追問的地方沉默了。因為AI實在太順手了,順手到會讓人誤以為「順」就等於「對」。
說了這麼多,有一點可以預見的是,AI agents 只會越來越強,這是大勢所趨。未來真正拉開差距的,很可能不再是誰用了更貴更強大的 AI。誰的業務流程設計得更深,誰更懂行,誰能始終把「人」留在這個決策迴路裡,誰就站得更高,走得更遠。
所以,與其一開始就讚嘆技術多厲害,我們更值得投資的是一種團隊習慣:把 AI 當作加速器和草稿機,把思考和判斷留給自己。
【張Sir講白話:用AI要帶腦睇路】
#人在迴路 #認知放棄 #HITL #AITL #AI Agent
@張Sir的AI養生館 – 學習智人
![[學AI] 讓思考看得見:中小學生如何善用 AI 做功課?](https://www.anguscheong.net/wp-content/uploads/2026/02/xie-zuo-03-1080x675.jpg)
by angus | 2026-02-11
很多大人看到中小學生用AI,心情複雜。一方面覺得這很方便,有效率,代表進步;另一方面也擔心,學生做功課像叫外賣,只顧「會吃」,卻忘了「會做」。
這份不安很正常。學生的大腦還在長骨頭,長的不只是詞彙量,還有注意力、理解模型、判斷力,以及對自己負責的習慣。AI 一旦進教室,最容易被偷走的,往往不是分數,而是那段慢慢長出能力的過程。
在上一篇中 [按此閱讀],我借用了兩個概念來拆解差別:「認知卸載」,是把部分工作交給工具,方向盤仍在自己手上;「認知放棄」,是連推理、判斷、責任也一起交出去,看見順滑輸出答案就當作完成。這一篇重點在一個更敏感的問題:學生怎樣用 AI 做功課,才不會不知不覺滑向「認知放棄」?寫作只是其中一種形式,理科題、閱讀報告、專題簡報,同樣存在風險。
「先想再用」是方向盤
我們常把 AI 視作會吐答案的機器,其實它更像班上那位總在課間幫同學做作業的「神助攻」:速度快、表情淡定,還總能把錯題講得好像自己全對過一樣。老師都得特別留神,學生哪能不被吸引住。
最常見的情境是,學生把題目貼進 AI 對話框,拿到一段看似完整的答案,然後就複製或下載。他以為自己學懂了,其實只是完成了交功課的動作。
答案對不對當然重要,更要緊的是,他有沒有經歷過思考。學習的肌肉不靠閱讀答案長大,靠的是推敲、撞牆、修正、再試。答案來得太快,學生就少機會在卡住的地方鍛鍊出理解力。
因此,課堂裏更容易出現「認知放棄」,原因很現實。時間緊、評分只看成品、能力又仍在成形,AI 很容易由工具變成代勞者。學生一旦習慣直接把答案交出去,久而久之就會忘了腦袋本來要用來判斷和推理。
- 時間壓力:功課多、考試近,最快完成的捷徑永遠最誘人。
- 回饋機制:目前的評分只看成品,學生自然把心力放在「看起來像完成」。
- 能力仍在成形:注意力、判斷、責任習慣尚未穩定,容易把工具當終點。
把 AI 放在「教練位」:它負責提問,學生負責思考
若學生一開始就找 AI 拿答案,看到的只是一份完成度高的作文、報告或解題過程,卻看不到思考痕跡。那種「做得很像懂了」的狀態,就是我說的「熟口熟面」:像學會了,實際上只是借了個殼。
更穩妥的做法,是把 AI 放到「教練位」。教練不會替你跑全程,它擅長的是追問與拆台:你怎樣得出這個結論?憑什麼這麼說?有沒有反例?前提站得住嗎?換個場景還成立嗎?換題型還適用嗎?
學生需要的正是這種提問。很多人不是不會想,是不知道從哪開始;AI 用得好,能把「開始思考」變得更容易。
一個最小可行流程:學生先出骨架,AI 只負責提問
我們可以設計一個簡單的流程,讓它易落地,重點在順序。先讓學生動腦,再讓 AI 進場。
首先,讓學生寫骨架:理科題寫明已知、要求、擬用公式或定理,以及每步邏輯。用自己的話列出解題思路、立場、理由、概念、例子與結論,粗糙無妨,反而看得出真動過腦。
接著,讓 AI 當教練提問,針對骨架發問,例如:
- 這一步依賴的前提是什麼?
- 有沒有反例或例外?
- 這個例子能代表整體嗎?
- 換個情境或題型還成立嗎?
- 結論能否收斂一點,避免說過頭?
最後,學生重寫定稿,將答案轉為自己的表述,補漏、修正、補充例子或推導,提交真正的「學生版本」。
這一步就像練功房:AI 是沙包,你打它,它回彈;你就知道哪裡力道不足。打完一輪再補一輪,肌肉才長在自己身上。
家長和老師看什麼:看思維痕跡
家長與老師若想配合這個流程,可以先從「看痕跡」開始。
當 AI 能把成品修得很光滑的時候,越需要回頭找痕跡。例如,我們可以拿幾個實用的觀察點來測試一下:
- 能不能口頭復述?學生講不出來就很危險。
- 能不能指出一個反例?學生只會順著說,通常是借來的理解。
- 能不能說出自己改了哪裡?改動越具體,思考權越可能在學生手上。
老師那邊若願意把評核的一小部分放到過程上,像草稿骨架、AI 提問回合、重寫版本,往往比單一成品更能反映學習。
這些做法看似麻煩,其實是把兩件事放回學習核心:讓學生在乎準確性,並得到即時反饋。當學生知道「思考過程會被看見」,他才更願意抵抗「認知放棄」,握回學習的方向盤。
回歸教育的本質
一直以來,抄襲至少一眼看得出來。學生抄了,多半也知道自己做了甚麼。但「認知放棄」一旦成習慣,長期下去更危險。這種麻煩不在一次作業的對錯,而在於它會慢慢變成學習方式。它會令學生感覺自己很努力——複製貼上也要動手,潤色改寫也花時間。這份努力非但沒長在思考上,反而貼在包裝上,看起來還很光明正大。
所以這篇先做一件事:把順序調過來,先想再用,讓思考過程重新被看見。我的目的很簡單:使用 AI 時,讓學生仍然有理由去思考,並得到針對思考過程的真實反饋。AI 沒有改變學習的核心,它把另一件事放大了:答案變得更容易拿到,學生也更容易跳過思考。當答案像自來水一樣隨手可得,真正稀缺的就回到人身上:學生有沒有想清楚問題,能不能質疑,願不願意為自己的答案負責。
@張Sir的AI養生館 – 學習智人
![[學AI] AI寫作最大的誤區:你幹了,卻不負「責任」](https://www.anguscheong.net/wp-content/uploads/2026/02/ai-xie-zuo-01-1-1080x675.jpg)
by angus | 2026-02-10
您是否經常在網上看到這樣熟悉的畫面:有人把一篇 AI 寫的文章貼出來,底下留言清一色說「寫得真好」、「太有才了」,往往只有一個留言說:「是真的嗎?」
那句話像針一樣扎進來。因為很多時候,我們不是寫不出來,我們只是太容易「交到一份看起來像完成」的東西。AI 把文字變得很便宜,便宜到你只要願意,幾秒鐘就能把頁面填滿。可寫作真正昂貴的部分,是吸收、理解、判斷和責任。[閱讀上一篇:請槍 AI 寫文零成本!「像我」誰負責?]
當下AI 寫作像一種新世代的「即食麵」:熱水一沖就能吃,香味也不差。問題在於,你吃完會有一種錯覺,以為自己會煮飯了。下一次有人問你「這味道怎樣來的?火候怎樣控?材料在哪裏買?」
無言以對。
當下,AI 把寫作變得太容易了,容易到我們開始分不清自己是在學AI,還是在用一個很會說話的工具替自己完成作業。文字通順、結構完整、例子齊全,真正的麻煩往往藏在更底層:我們越來越快得到內容,卻越來越少把內容變成自己的能力。
接下來幾篇文章,我會分場景談:一般作者如何與 AI 協作、怎樣避免被工具牽著走;中小學怎樣用 AI 又不偷走孩子的腦袋;高等教育怎樣把 AI 變成論證與研究的助力,而非剪貼機;職場怎樣用 AI 提升決策與風險控制,而非只做漂亮交付;再往後把整套方法系統化,用多 Agents 配合人在回路(HTIL)的流程,以及談談如何落地,搭一條「寫作裝配線」。
這系列有一句主旋律,我會反覆講,但每次會落在不同地方:AI 把獲取變便宜,吸收、理解、判斷和責任變昂貴。方法的任務,是把昂貴那段拆成可承受、可重複的步驟。
這篇我先把底層邏輯講清楚。AI 更像一面放大鏡。我們原本有骨架,它會幫我們加速;原本欠骨架,它也會把空洞放大。
先講清楚:我們以前怎樣把「不知道」變成「知道」
在 AI 出現以前,知識獲取大多像爬一座高聳的金字塔。最底層是符號(字、圖、數字),往上是訊息(符號有了指向)、再往上是資訊(訊息被整理後能用來回答某些問題),最後才是知識(你能解釋、能推理、能預測、能把它用在新情境)。
這條路徑很慢,也很煩。慢在我們得找資料、讀原文、做筆記;煩在你常常卡住:看懂了,卻不會用;以為懂了,一問就露底。可那種「卡住」其實很值錢,因為它迫使我們把腦袋裏的理解框架一點點搭起來。
AI 時代最不一樣的地方在於,它把這座金字塔的前幾層直接「跳級」了。
AI 時代:從線性爬塔,變成跳躍式走捷徑
AI 的厲害,在於它把「符號→訊息→資訊→知識」變得像自來水。你丟幾個關鍵詞,它就替你把符號整理成訊息,把訊息整成資訊,再包裝成一段看起來像知識的文字,語氣還很篤定。
以前你得一層層爬;現在更像坐電梯直達頂樓,門一開,眼前是一份完整的「答案」。答案一完整,我們就更容易把它當成知識。跳躍式、非線性的獲取,最常帶來兩個後果:理解被跳過、責任也被跳過。
把這兩個詞先弄懂:認知卸載 vs 認知放棄
講到這裏,必須把兩個容易混在一起的概念先弄懂,否則後面所有方法都會跑偏。因為,其實以下兩件事我們很早就做過了;AI 只是把它們放大,放大到你不想面對也不行。
- 認知卸載(cognitive offloading):我們策略性把一部分工作交給工具,例如計算、整理、提醒。通俗一點,我們把「搬磚」的工作外判出去,但方向盤仍在自己手上。我們仍然要決定何時用、用在哪裏、結果要不要覆核。不是嗎?電子計算機把心算筆算載掉,互聯網把去圖書館查資料卸載掉,手機把行程、導航、電話號碼卸載掉。我們省力了,還是知道自己要去哪裏、打電話給誰、在解決甚麼問題。
- 認知放棄(cognitive surrender):我們把推理、判斷、責任也交給工具。也就是說,我們把方向盤也外判了。看到 AI 輸出順滑、自信,就當作完成。 這也不是 AI 才有的毛病。早年「谷歌一下」就讓人養成不回頭看來源的習慣;後來推薦算法把我們愛看的內容一路餵到嘴邊,慢慢忘了自己原本想問的問題。AI 則更進一步,連「看起來很合理的結論」都準備好,我們連懷疑都省掉。
前幾天讀到來自沃頓商學院的研究人員剛發表的一份工作論文,用「認知放棄」描述他們在三項預註冊實驗中觀察到的一種行為傾向:人們往往幾乎不加質疑地接受 AI 的輸出,同時忽視直覺判斷與深思熟慮的推理過程。AI 回應快、語句流暢、聽起來合理,很多人就覺得「可以了」。他們也指出,當受試者有動機在乎準確性,並能即時得到自己的表現反饋時,更願意拒絕錯誤輸出,並主動去思考。
把這段研究發現放回寫作場景,意思是說,AI 既能做卸載,也很容易把人推向放棄。差別不在工具本身,而在於有沒有把主導權握住。
AI寫作最常見的三個坑:看似高效,實際空心
我見過通常的誤用,離不開以下三個坑。它們看起來不同,本質上都指向同一件事:把思考能力交出去。
第一個坑:把 AI 當成答案販賣機。題目一丟、草稿一收、稍微改幾句就交。成品看起來體面,但一追問「這個論點憑什麼成立?如果有人質疑,怎麼回應?」很多人會卡住。因為過程裏大腦沒有真正出力,突然覺得短路了。
第二個坑:把「看過」誤認成「懂了」 。答案看起來「熟口熟面」。讀起來很順,覺得自己認得它,就以為自己懂得了它。像你看別人彈鋼琴,知道下一個音會落在哪裏,輪到自己上手,手指一樣打結。我們得到的是熟悉感,不是能力。
第三個坑:把速度當成能力。 AI 能把產出速度拉到以前想都不敢想的程度,於是我們用「完成」來安慰自己:稿交了、簡報出了、報告送了。完成只是交付;能力成長要看有沒有形成理解框架、有沒有做過取捨、有沒有負過責任。
三個坑疊在一起,就會很尷尬:做得更快、更像樣,判斷力與理解力沒有同步長大。一換題目、一換情境、一換要求,整個人像熟練按鈕的人,不像掌握技藝的人。
分水嶺:你把哪一段交出去?你自己保留哪一段?
常見的誤用做法,是把「思考的主幹」交了出去,把「表面的修飾」留給了自己。AI 給論點、結論、結構,我們做潤色和拼貼。省時是真的,最能培養能力的部分則被外判了。
當我們能善用AI時,判出去的是勞動密集、可替代的部分;保留的是需要負責、不可替代的部分。AI 幫我們補材料、找例子、改寫表達、列對照;而我們自己可決定這篇文章要解決甚麼問題?採用甚麼立場?哪些假設站得住?哪裡需要查證?哪裡要承擔風險?
也就是說,AI 讓答案變得很便宜,負責任的判斷則更值錢。
為甚麼答案越容易得到,理解反而越困難?
寫作像爬一條從符號到知識的梯子。以前最難的是前半段:資料難找、例子難挖、表述難寫。AI 把這些成本壓到接近零,瓶頸就往知識金字塔的上端移動——移到人類不得不親自出力的地方。
而這些地方,恰恰是最費時、最昂貴的:
- 注意力:能不能把心神固定在一個問題上足夠久,不被隨手可得的輸出牽著跑。
- 理解力:腦中有沒有可運行的解釋框架,能不能講清楚「為甚麼」與「所以呢」。
- 判斷力:在多個看似合理的選項裏如何取捨,如何處理不確定,如何定義好邊界,在哪裡結束。
- 負責任:哪些話需要查證?哪些是恰當的比喻?哪些結論若錯了會誤導誰?最終,署名的是作者本人。
我的方法:HITL+AITL,把AI協作做成可複製的寫作工坊
為了將力用在可承受、可重複的流程裡,逼自己不要把寫作的方向盤交出去,我把 AI 寫作流程設計成一間小型工坊,每一步都留下可檢查的交接件,避免只拿成品、不見能力。
這裏我特意引入了AI技術裡的兩個概念到這套流程中:
- HITL(human-in-the-loop)人在回路:流程裏設計幾個「人必須停下來做判斷」的關口。關口的目的是把主導權、取捨權、責任留在自己手上。
- AITL(AI-in-the-loop)AI在回路:讓 AI 成為流程中的工作站,負責供給、拆台、校對、讀者測試等勞動密集工序。AI 不是終點,它是回路中的一個工位。
兩者配合起來,效果就像一個我經常使用的比喻:廚房—AI 可以備料、切菜、洗碗、列菜單;人要試味、決定火候,最後出菜。廚師可以請很多幫手,味道終究要他負責。
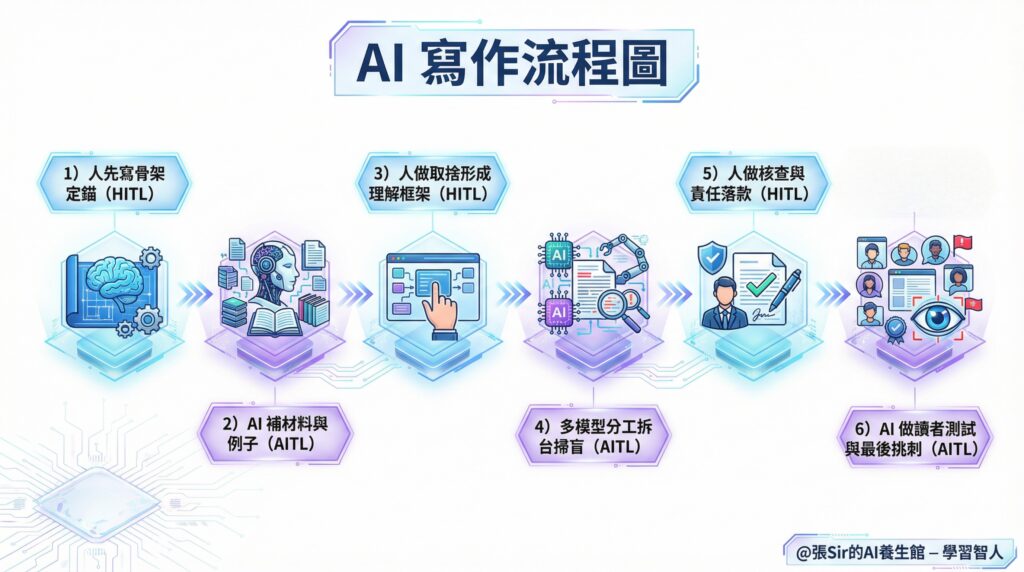
具體的流程如下:
- 先由人定錨(HITL):先寫骨架。哪怕粗糙也行:一句主張、三個理由、可能的反例、讀者最常問的問題。方向盤先握回來,觀點先由自己決定。
- 再由 AI 供給(AITL):補材料、舉例、改寫。它提供候選項,自己挑、剪、取捨。
- 中段用人做取捨(HITL):組織、刪減、補充,逼自己形成理解框架。資料堆高很容易,取捨清爽才見功力。
- 用不同模型做角色切換(AITL):設計助理來補例證,做反方專門提問「憑什麼」。模型偏好不同,盲點更容易被照出來。當然,這個流程節點必須具備使用多個AI模型做前提。
- 最後回到人核查落責(HITL):校對、驗證、加邊界、補來源,必要時刪掉無法核查的段落。這一步沒人能替自己做。
- 最後再請 AI 做讀者測試與挑刺(AITL):扮演目標讀者、審稿人、反對者,把最後一輪漏洞逼出來。
用一個流程圖來顯示,看起來是線性,但在實際執行過程中,總會來回切換,這一點必須提醒一下。
寫到這裡,這篇也差不多收筆。如果你也想訓練自己對抗「順滑感」帶來的「認知放棄」,不妨先問問:
- 這句話是事實、推測,還是比喻?
- 依據在哪裏?能追到哪個來源?
- 若錯了,會誤導誰?代價是甚麼?
- 我願不願意為這篇文章署名?
然後,你會發現一個很微妙的現象:AI 幫了你很多,但你仍然很忙。忙的那段,正是吸收、理解、判斷與責任。
這反而是好事,因為你會更堅定地願意為你的成品署名。
參考資料
Shaw, S. D., & Nave, G. (2026). Thinking fast, slow, and artificial: How AI is reshaping human reasoning and the rise of cognitive surrender. Working paper, The Wharton School, University of Pennsylvania. SSRN: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6097646
@張Sir的AI養生館 – 學習智人

by angus | 2026-02-08
昨天跟國學大師前輩閒聊時,話題繞到 AI,我先忍不住自嘲了一句:我有時也會一本正經地胡說八道,而且胡說得很像那麼回事。AI 幻覺最可怕的地方也在「像」——像到你自己都差點信了,像到旁人也懶得追問,像到它可以被轉發、被收藏、被當成一句「很有智慧」的話供奉起來。
回到家裡,看到大師的FB貼子,以「大師口吻」寫了句:反省問題,撥開雲霧,自見青天,閃耀生命的智慧。乍看字字端正,句句像在說真理。可越是這樣的句子,越讓我心虛:我真的會寫說這段話嗎?我究竟想說什麼?
租來的古裝,撐不起自身的學問
這一問,問題就回到我剛剛使用AI的經歷——我曾經很認真地玩AI,玩到有點走火入魔:把 AI 調教成「像我」,再順手裝扮成「像我喜歡的那些人」。沈從文、魯迅、金庸、莎士比亞、海明威……名字一輸入,像在餐牌QR code上掃一掃,下一秒菜就端上來,熱騰騰的,語氣、節奏、比喻都「像」。既爽快又充滿虛榮感:明明只是打了幾個字,卻像忽然多了幾十年筆齡的大師,連停頓都安排得像模像樣。
可能也正因為太順了,很快就開始感到不安。太順的東西往往需要付出代價。回頭想想,我當時迷戀的多半也不是「寫得更好」,而是「看起來更像」——像某種成熟,像某種老練,像我希望別人以為我已經變成的那個自己。
然後冷靜下來細想,問題其實很簡單:我真的是沈從文嗎?讀者會認為我是沈從文嗎?就算他覺得像,也多半只會覺得我在請槍模仿。這件事像極了在旅遊景區租了一套古裝去拍照,燈光打得剛好、表情也能撐住,照片看起來挺有古氣派;但心裏清楚,那不是我,我只是穿越了一下而已。
沈從文那種溫柔得像水的筆法,是他看遍了湘西的人情冷暖、經歷了時代的動盪後,選擇用悲憫去包裹苦難。魯迅那種尖刻,是他對國民劣根性的痛心疾首,是他在黑暗中吶喊的代價。AI 模擬的只是他們的「語氣參數」,是通過大數據計算出來的概率分佈,把最常出現的字詞重新組合而已。它沒有經歷過那些苦難,不需要為那些觀點承擔風險。當把這種風格套在自己身上時,得到的只是一個空殼。
內容的本質:邏輯與責任
在學習與知識傳播的領域裏,必須釐清一點:寫作和表達的核心,始終是邏輯、判斷與責任。
讀者花時間讀你的文章,聽你的報告,不是為了看你玩弄辭藻,也不是為了看一場模仿秀。他們想要的是一個清晰的觀點,一個能解決問題的模型,或者一種對世界的獨特判斷。
如果文章的觀點是 AI 拼湊的,邏輯是 AI 演繹的,連情感都是 AI 模擬的,那麼請問,作者在哪裏?
這就是 AI 時代最大的荒誕之處:文字的生產成本已經降到了零。一分鐘生成一百篇風格各異的文章毫無難度。但正因為「量」的泛濫,「質」的稀缺性才更加凸顯。這個「質」,指的不是文筆,而是「責任」。
作者敢不敢為這句話負責?能不能為這個判斷背書?
金庸筆下的江湖有情有義,AI 可以模仿那種豪氣,但它不懂什麼叫「俠之大者,為國為民」。如果作者只是用 AI 生成了一堆漂亮的江湖黑話,卻說不清自己的價值觀底線,讀者感受到的只會是空洞。就像收到一封印刷精美的信,打開來卻是一張白紙,連個簽名都沒有。
把 AI 當成「諍友」,而非「槍手」
經過了兩年的嘗試,「像我」其實很沒必要。讀者來這裡讀文章,多半不是來參觀文風的,他們想帶走的是一個更清楚的理解模型,一套能用在生活或工作裏的尺度。即使我讓 AI 把句式模仿得再像,如果觀點是空的,讀者記不住;如果邏輯站不住,讀者用不上;如果責任不清楚,讀者只會覺得我很會說,卻不太可信。
所以後來我逐漸轉向,不再要求 AI 像我。我寧願它像我那個最不喜歡、但最有用的朋友——會拆台、會追問、會逼我交代「憑什麼」這樣寫。它可以冷一點、硬一點都無所謂,只要它能把我的漏洞找出來,我就知道自己在哪裏偷懶,在哪裏想用漂亮話混過去。
在教學相長的過程中,我更願意把 AI 設定成一個「挑剔的教授」或者「冷酷的辯論對手」。我會讓它:
- 邏輯拆解:找出我論述中的邏輯漏洞,質問我的數據來源是否可靠。
- 降維翻譯:把我的學術黑話翻譯成大眾讀者聽得懂的大白話(這點它做得比我好,這是它的強項)。
- 視角擴展:提供我不熟悉的領域案例,打破我的「知識同溫層」。
我寧願它冷冰冰地指出我的錯誤,也不要它溫情脈脈地模仿我的口吻。前者能讓我的思維肌肉更結實,後者只會讓我患上「認知癡呆症」。
放棄請槍,做回大腦的執行官
在「張Sir的AI養生館」裡,我常說要把身體外包給自己,其實大腦的主導權更不能外包。
在 AI 時代,風格是最廉價的「皮膚」,隨時可以更換。真正值錢的,是作為一個「人」的痛感、猶豫、選擇,以及願意為這些選擇付出的代價。
這或許才是人類應有的學習AI的態度。
【張Sir講白話:學其骨,不學其皮】
- 拒絕請槍心態:花時間調教 AI 的語氣,不如花時間打磨核心觀點與邏輯架構。
- 警惕順滑感:AI 生成得越順,越要警惕,因為真正的深度思考通常是粗糙且痛苦的。
- 責任不外包:AI 可以寫草稿,但發布按鈕必須由作者來按,觀點的責任由作者來擔。
- 尋找異見者:用 AI 來挑戰思維盲區,讓它做「紅隊」(Red Team)。
- 真實最貴:在萬物皆可生成的年代,那點帶着瑕疵的真實感與個人經驗,才是最稀缺的資產。